更新时间:2023-05-11点击:1208
当下,国内外的智能AI大模型越来越多了,国际上的ChatGPT、Vicuna-13B,国内有讯飞星火认知大模型、文心一言知识增强大语言模型等,那么这些大模型在中文测评中又有怎样表现呢?或许5月9日发布的中文通用大模型综合性评测基准SpuerCLUE(A Benchmark for Foundation Models in Chinese)可以给我们答案!
三大能力维度客观全面测评
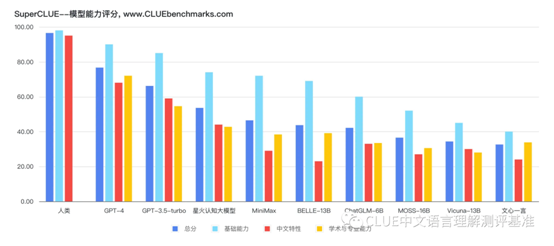
SuperCLUE测试基准针对的是中文可用的通用大模型的一个评测基准,包括但不限于这些模型不同任务的效果情况,以及对比国际上代表性模型和人类对比的效果。同时,SuperCLUE测试基准也发布首期测评榜单,主要由总榜单、基础能力榜单和中文特性榜单构成,包含了基础能力、专业能力和中文特性能力三大维度测试,测试的能力还是很全面的,并且还拥有自动化评测、广泛代表性和采取人类基准等特点,较为客观的对当下通用大模型的能力进行了全面测评。

各类大模型中文测评表现
本次公布的榜单中,人类的测评表现最佳这也是毋庸置疑的,GPT-4排名第一,国内排名中讯飞星火认知大模型表现最佳,仅在GPT-4和GPT3.5-turbo之后,总分为53.58,位列第三。百度的文心一言知识增强大语言模型总分32.61,排名靠后,而国际表现良好的Vicuna-13B却排名倒数第二。在计算能力上人类表现最佳,领先表现最好的GPT-4 30个百分点,而在语义理解中,排名第三的讯飞星火认知大模型也是领先排名第一的GPT-4。但从综合角度来看,国内的GPT和国际领先的GPT还是有一定差距,不过差距有望追赶。
5月6日成果发布的讯飞星火认知大模型在SuperCLUE测试基准测试中取得的国内第一的好成绩,并且在语义理解、百科和知识、对话等测评中都展现了不错的能力,尽管和国际领先的GPT还存在差距,但对于持续迭代、不断进化后的讯飞星火认知大模型,笔者还是报以很大的期待。